Matrix Multiplication based on the RISC-V Vector Extension
Luffcaでは、RISC-Vベクトル拡張(RVV)に基づく行列積カーネルを作成し、RTLシミュレータを用いて性能を評価しました。
関連記事は、こちら。
- Running Auto-Vectorized Program on RISC-V Vector RTL Simulator
- Matrix Multiplication based on the RISC-V Vector Extension(本記事)
- 1×1 Convolution based on the RISC-V Vector Extension
Matrix Multiplication
行列積カーネルは、n × mの行列Aとm × pの行列Bから、その積であるn × pの行列Cを計算します(C=AB)。行列Cのi行j列の成分をc_{ij}とすると、c_{ij}は以下の式で表されます。
![]()
ベクトル化前のコードは、以下のようになります。
// C = AB with A = [n x m], B = [m x p], C = [n x p]
void matmul_int8(int32_t* c, const int8_t* a, const int8_t* b,
const unsigned long int n, const unsigned long int m,
const unsigned long int p) {
for (int i = 0; i < n; ++i) {
for (int j = 0; j < p; ++j) {
int32_t sum = 0;
for (int k = 0; k < m; ++k) {
sum += a[i * m + k] * b[k * p + j];
}
c[i * p + j] = sum;
}
}
}
機械学習への応用を考慮し、行列AとBの成分はint8_t、行列Cの成分はint32_tとしています。
以前の記事では、LLVM/Clangの自動ベクトル化をテストしましたが、今回はハンド・チューニングにより、行列積カーネルを作成しました。
Ara
Araは、PULP(Parallel Ultra Low Power)プロジェクトで開発されているRISC-V Vector Extensionの実装です。Araのリポジトリには、以下の記述があります。
Ara is a vector unit working as a coprocessor for the CVA6 core. It supports the RISC-V Vector Extension, version 1.0.
Araは、laneと呼ばれている64-bitベクトルユニットの実装数により、スケーラビリティを確保しています。configディレクトリには、Araシステムの構成として[2|4|8|16]_lanes.mkが用意されています。各laneには、ALU(Arithmetic Logic Unit)、MUL(integer multiplier)、FPU(Floating Point Unit)が含まれており、64-bit幅の整数演算や倍精度の浮動小数点演算を実施できます。
なお、引用文中のCVA6は、以前にPULP Arianeと呼ばれていた64-bit RISC-V coreです。
Matrix Multiplication on Ara RTL Simulator
Araは、Verilatorを用いてAraシステムのRTLシミュレータを作成できます。今回は、デフォルト構成の4_lanes.mkを使用しました。
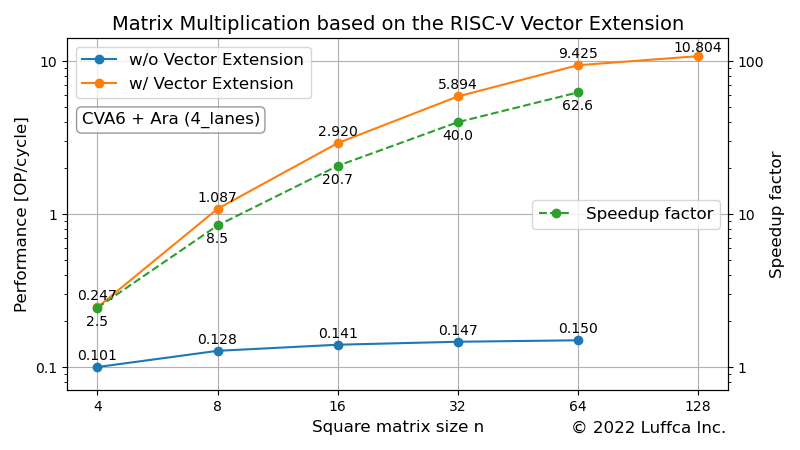
以下は、作成した行列積カーネルを実行しているときのコンソール出力を示しています。
$ cd $ARA/hardware $ app=imatmul_int8 make simv ... ============= = IMATMUL = ============= ... ------------------------------------------------------------ Calculating a (32 x 32) x (32 x 32) matrix multiplication... ------------------------------------------------------------ Initializing matrices... Calculating imatmul... The execution took 11119 cycles. The performance is 5.894055 OP/cycle. Verifying result... Passed. ------------------------------------------------------------ Calculating a (64 x 64) x (64 x 64) matrix multiplication... ------------------------------------------------------------ Initializing matrices... Calculating imatmul... The execution took 55627 cycles. The performance is 9.425063 OP/cycle. Verifying result... Passed.
CVA6のサイクル数との比較では、32 x 32の行列積の場合、40倍スピードアップ、64 x 64の行列積の場合、62倍のスピードアップを実現しました。
まとめ
Luffcaでは、RISC-Vベクトル拡張に基づく行列積カーネルを作成し、AraのRTLシミュレータを用いて性能を評価しました。