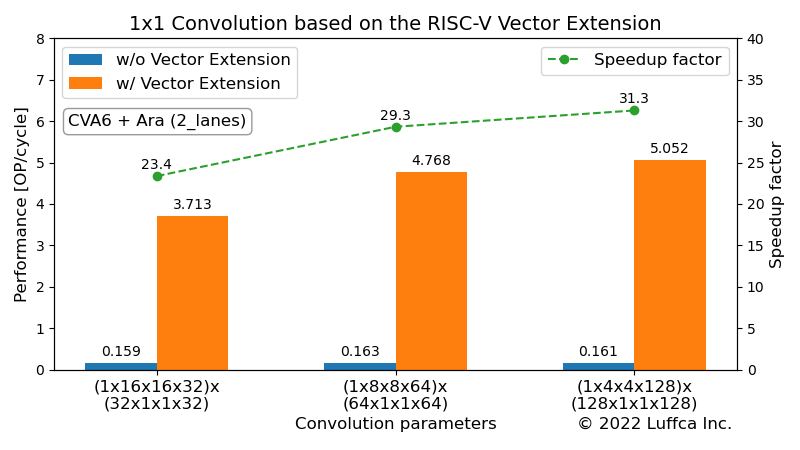
1×1 Convolution based on the RISC-V Vector Extension
Luffcaでは、RISC-Vベクトル拡張(RVV)に基づく1×1 convolutionカーネルを作成し、RTLシミュレータを用いて性能を評価しました。
関連記事は、こちら。
- Running Auto-Vectorized Program on RISC-V Vector RTL Simulator
- Matrix Multiplication based on the RISC-V Vector Extension
- 1×1 Convolution based on the RISC-V Vector Extension(本記事)
1×1 Convolution
1×1 convolutionは、サイズがHxWxCの入力の各(h, w)と、サイズが1x1xCのフィルタとの内積を出力チャンネル毎に計算します。
TensorFlow Lite for Microcontrollersを参照したベクトル化前のコードは、以下のようになります。
// output_data = 1x1_conv((input_data + input_offset), filter_data) with
// input_data = [B, H, W, C], filter_data = [OC, 1, 1, C],
// output_data = [B, H, W, OC]
void OneByOneConvInt8(const int8_t* input_data, const int8_t* filter_data,
int32_t* output_data, const int32_t input_offset, ...) {
...
for (int batch = 0; batch < batches; ++batch) {
for (int out_y = 0; out_y < output_height; ++out_y) {
const int in_y = out_y;
for (int out_x = 0; out_x < output_width; ++out_x) {
const int in_x = out_x;
for (int out_channel = 0; out_channel < output_depth; ++out_channel) {
int32_t acc = 0;
for (int in_channel = 0; in_channel < input_depth; ++in_channel) {
int32_t input_val =
input_data[Offset(input_shape, batch, in_y, in_x, in_channel)];
int32_t filter_val = filter_data[Offset(filter_shape, out_channel,
0, 0, in_channel)];
acc += (input_val + input_offset) * filter_val;
}
output_data[Offset(output_shape, batch, out_y, out_x, out_channel)] =
acc;
}
}
}
}
}
なお、input_dataとfilter_dataはint8_t型配列、output_dataはint32_t型配列です。
Ara
Araは、PULP(Parallel Ultra Low Power)プロジェクトで開発されているRISC-V Vector Extensionの実装です。Araの概要は、関連記事のMatrix Multiplication based on the RISC-V Vector Extensionをご覧ください。
1x1 Convolution on Ara RTL Simulator
Araは、Verilatorを用いてCVA6とAraを組み合わせたAraシステムのRTLシミュレータを作成できます。今回は、64-bitベクトルユニットを2つ備えた最小構成の2_lanes.mkを使用しました。
以下は、作成した1x1 convolutionカーネルを実行しているときのコンソール出力を示しています。
$ cd $ARA/hardware $ app=1x1_conv_int8 make simv ... =================== = 1X1 CONV INT8 = =================== -------------------------------------------------------------------- Calculating a (1 x 16 x 16 x 32) x (32 x 1 x 1 x 32) convolution... -------------------------------------------------------------------- Initializing data... Calculating 1x1 conv without vector extension... The execution took 3300106 cycles. The performance is 0.159 OP/cycle. Calculating 1x1 conv with vector extension... The execution took 141214 cycles. The performance is 3.713 OP/cycle. Verifying result... Passed. -------------------------------------------------------------------- Calculating a (1 x 8 x 8 x 64) x (64 x 1 x 1 x 64) convolution... -------------------------------------------------------------------- Initializing data... Calculating 1x1 conv without vector extension... The execution took 3224180 cycles. The performance is 0.163 OP/cycle. Calculating 1x1 conv with vector extension... The execution took 109951 cycles. The performance is 4.768 OP/cycle. Verifying result... Passed. -------------------------------------------------------------------- Calculating a (1 x 4 x 4 x 128) x (128 x 1 x 1 x 128) convolution... -------------------------------------------------------------------- Initializing data... Calculating 1x1 conv without vector extension... The execution took 3247290 cycles. The performance is 0.161 OP/cycle. Calculating 1x1 conv with vector extension... The execution took 103775 cycles. The performance is 5.052 OP/cycle. Verifying result... Passed.
入出力チャンネルが32、64、128の場合、CVA6に対して23〜31倍のスピードアップを実現しました。
まとめ
Luffcaでは、RISC-Vベクトル拡張に基づく1x1 convolutionカーネルを作成し、AraのRTLシミュレータを用いて性能を評価しました。