Building an ML Processor using CFU Playground (Part 3)
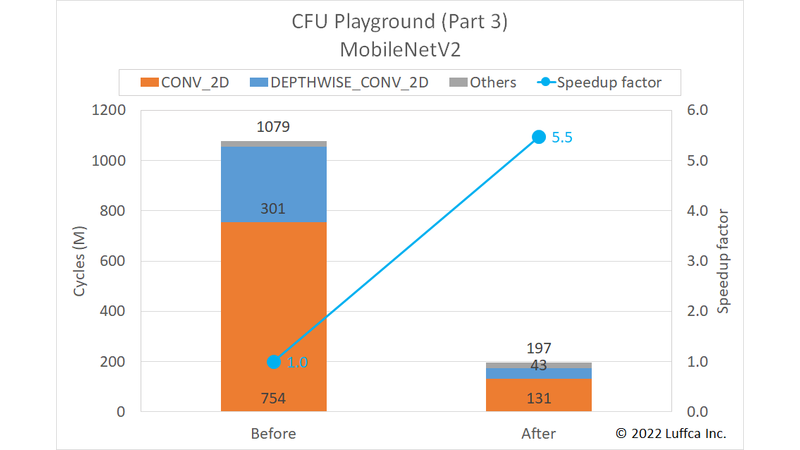
We have built a machine learning (ML) processor on an Arty A7-35T using CFU Playground. In Part 3, we have accelerated the inference of MobileNetV2 by 5.5 times.
CFU stands for Custom Function Unit, which is a mechanism to add hardware for RISC-V custom instructions in LiteX-VexRiscv.
Click here for related articles.
- Part 1: Person Detection int8 model
- Part 2: Keyword Spotting model
- Part 3: MobileNetV2 model (this article)
CFU Playground
CFU Playground is a framework for tuning hardware (actually FPGA gateware) and software to accelerate the ML model of Google’s TensorFlow Lite for Microcontrollers (TFLM, tflite-micro).
See the Part 1 article for more details.
MobileNetV2
MobileNetV2 is the successor to MobileNetV1 which is famous as a lightweight model. It is a model that incorporates the structure of inverted residuals and linear bottlenecks while following the depthwise separable convolution of MobileNetV1.
The figure below, quoted from arxiv paper, shows the inverted residual block in MobileNetV2.
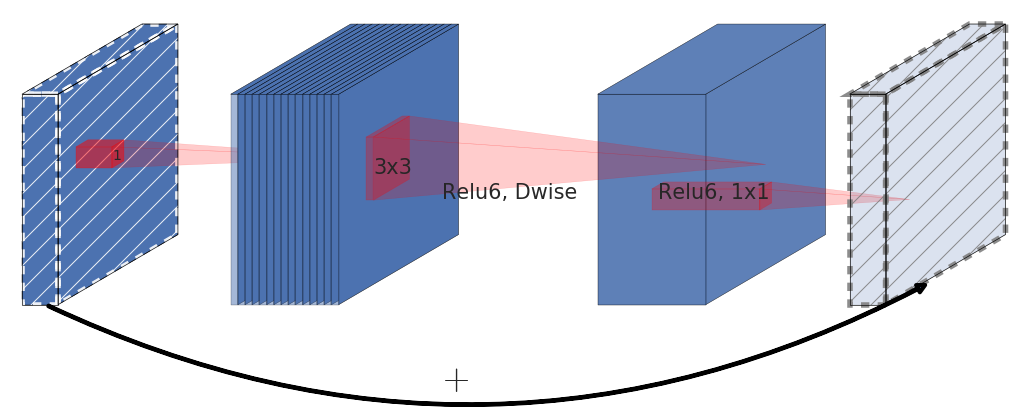
For more information on MobileNetV2, see the arxiv paper.
multimodel_accel project
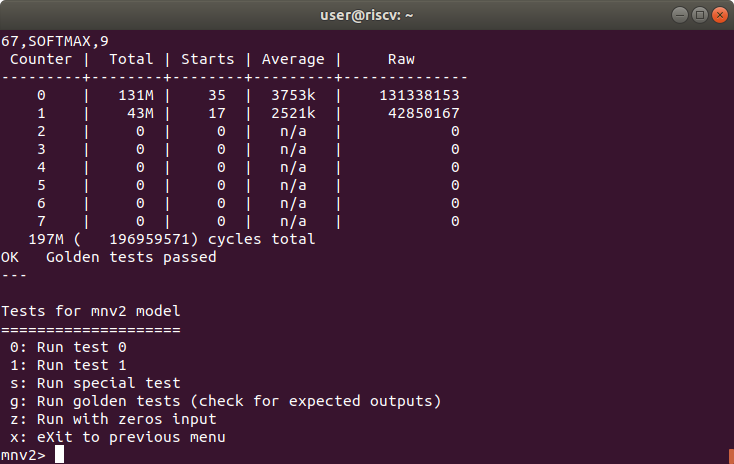
Result of golden tests for MobileNetV2 model
The multimodel_accel project is an in-house project that aims to accelerate multiple ML models, while most CFU Playground projects are model-specific to accelerate only one ML model.
As shown in the console image above, MobileNetV2 is called the mnv2 model in the CFU Playground.
Introducing the results first, as shown in the featured image and the table below, the total number of cycles of the mnv2 model has been reduced from 1079M to 197M, achieving a 5.5x speedup.
Note that our project is even twice as fast as the CFU Playground mnv2_first project, which accelerates the total number of cycles of the mnv2 model to 397.5M.
| MobileNetV2 | Cycles | Speedup factor |
|
|---|---|---|---|
| Before | After | ||
CONV_2D |
754M | 131M | 5.8 |
DEPTHWISE_CONV_2D |
301M | 43M | 7.0 |
| Others | 24M | 23M | 1.0 |
| Total | 1079M | 197M | 5.5 |
Since it is a multimodel_accel project aimed at accelerating multiple ML models, the Person Detection int8 (hereafter pdti8) model in Part 1 has been accelerated from 48M to 38.4M, and the Keyword Spotting (hereafter kws) model in Part 2 has been accelerated from 15.7M to 9.8M.
Software Specialization & CFU Optimization
The multimodel_accel project uses the 1×1 convolution (hereafter 1x1_conv) and the depthwise convolution (hereafter dw_conv), which are specialized and optimized for the pdti8 and kws models in addition to the mnv2 model.
In Part 3, we improved dw_conv, which has a smaller speedup factor than 1x1_conv in Part 1 and Part 2. Specifically, we have achieved speedup by making dw_conv, which was compatible with CFU in Part 1, compatible with single instruction, multiple data (SIMD). For this reason, we are changing both the gateware and the software.
Also, as the speed of other layers has increased, the processing time ratio of the first 2D convolution that is not 1x1_conv has increased, so a dedicated kernel has been added.
Summary
We have built an ML processor on an Arty A7-35T using CFU Playground. The ML processor can infer the MobileNetV2 5.5 times faster and run in 197M cycles.